I’m sitting in the Spring sunshine (it’s the UK so it’s cold) preparing my talk for the GSC conference in Windsor which starts tomorrow. This is a great venue as it gets representation from major carriers globally mostly concerned with Trading international traffic and the subsequent business processes that support that seemingly simple activity. Few thoughts are paramount, one of them is that I’m presenting on Thursday so there will be a lot of information sharing by then so I hope I would manage to glue the audience to their seats.
The theme of my presentation is Evolution of Partner Settlement. I think that the apparatus, systems, structures and know how which allows carriers to trade voice minutes will soon be in demand to negotiate, set prices and monitor a whole range of services and not just voice.
One particular area I’m interested in is content settlement. How does the carrier (or a cable company) set a fair price with a content creator? How does the content owner verify the final payment? If it’s all about supply and demand, how do providers gauge demand and look at product performance? Who could have predicted that a Danish sub-titled crime thriller, The Killer series, would take the world by storm? ( I guess the writer!)
What strikes me is that what Telcos sell changes, but not how successful business runs. I once worked in a toy shop in a particularly posh part of London. Our buyer made the company a fortune from buying Japanese pencils ( a bit like Hello Kitty) – everyone thought she was nuts. She also ceremoniously dumped the then unfashionable Kermit the frog. This released floor space, which she crammed with pencils and she watched point of sales like a hawk. Nowadays we have sophisticated systems such as ours to do this. But the core things that buyer spoke about, attractive stock, great presentation, customer experience are all key elements of product management and content distribution. Managing the content catalogue and getting value for the content creative and the CSP are critical.
So I’m hoping to have a great discussion about Partner Settlement with people this week about all the hot topics IPX, Content, M2M, Mobile Money – don’t ever let anyone tell you billing is boring.
Our story begins with Farmer Joe who has a beautiful daughter Janet. Farmer Joe decides to bequeath the family decorative pin to Janet on her 20th birthday. Now Janet, in a fit of unbridled joy decides to run around a haystack holding the pin towards the heavens. Suddenly,in a scene far too clichéd to be coincidence, she trips and the pin falls into the haystack…
Now begins the daunting task of “finding the pin in the haystack”. Janet is faced with a dilemma which would be quite familiar to RA analysts the world over – how do we find the pattern which highlights the root cause (or the pin, if you are a farmer’s daughter who goes by the name of Janet) within a world of millions of CDRs.
Of course, the solution is to cut the haystack into smaller cubes and search smaller segments for the pin. Does this sound familiar to you, my RA analyst friend? It should – because this is the way we attempt to find the root cause today. When your system presents you with millions of CDRs (or, God forbid, meaningless summaries), we tend to break them into smaller sets which have seemingly similar patterns. Then begins the back-breaking task of finding the elusive pattern that indicates the root cause – an endeavor that involves quite a few cups of strong coffee, pointless mails and shattered dreams regarding deadlines and analyst efficiencies.
But hey, this is how we do Root Cause Analysis the world over right? We would reduce our effort by managing the problem size right? Well, it gives me great pleasure to say that the winds of change are blowing. Today, I would like to introduce to you to a fundamental paradigm shift in Root Cause analysis which would effectively transform the way we do RA.
Let’s imagine for a second that Janet decides to find the pin by placing a powerful magnet over the haystack. Consider how much time and effort she saves, as compared to breaking the large haystack into smaller stacks. Consider how sure this solution is, as compared to the possibility of not finding the pin even after breaking the haystack into smaller segments.
Now imagine such a magnet for RA. A magnet that presents the analyst with all the hidden patterns in a problem set (discrepant CDRs). Imagine how this would change your day in terms of boosting analyst efficiency, achieving cost efficiencies as a department, being prepared to handle new and upcoming technologies and always staying one step ahead of the curve.
That magnet has a name, and its name is “Zen”. Subex recently launched ROC Revenue Assurance 5, and along-with RevenuePad (which my colleague Moinak would write about), Zen is one of the fundamental pillars of this ground-breaking solution.
Zen is an automated Root Cause Advisory engine which provides, for the first time ever, machine intelligence for pattern identification and presentment. What makes it revolutionary is that the engine is programmed to sniff out patterns with minimal involvement from the analyst. Give Zen two data sets, and it will tell you exactly why some CDRs in data set 1 are not present in data set 2. This also involves telling the analyst what percentage of the total data set can be linked to any particular pattern. Since pictures speak louder than words, here is a sample illustration:
Zen is essentially a data analytics engine for ROC Revenue Assurance 5. Based on the discrepant sets identified as the result of an audit, Zen automatically fires up the pattern analytics engine. As Zen works on identifying the patterns, it also works on linking the patterns to specific CDRs (to ensure that an audit trail would be maintained). Finally, Zen presents the analyst with a comprehensive view of:
All identified patterns in the discrepant data set
Distribution of how many CDRs are linked to which pattern
Historic event indicators to further guide the analyst towards the root cause
Zen is keyed towards two “Intelligent” actions:
Pattern Analytics
Analyst Feedback integration
We refer to Patterns as “Areas” and the learning from past investigations as “Reasons”. Why do we need both, you ask? The answer is fairly simple – the same pattern (or Area) might have presented itself for very different “Reasons”. A simple example of Subscriber profile between HLR and Billing might clarify this point.
An analyst, on performing the HLR vs Billing subscriber reconciliation, finds that 20 subscribers on the HLR are not present on the Billing platform. Now, in the absence of provisioning logs, he/she might surmise that this is a simple case of provisioning error and forward the information to the relevant teams.
However, if the same discrepancy is seen next week for the same set of subscribers, it might be prudent to address the possibility of internal fraud as well. Here we see an example where the same pattern (20 subscribers are missing repeatedly in billing but are provisioned on the network) might be due to two distinct “Reasons” – Provisioning Error or Internal Fraud.
Zen helps you tie it together. Reasons are incorporated into the Zen engine based on “Acknowledgments” received from various teams. This helps to ensure that “False Reasons” are minimized. In this manner, Zen becomes a repository of Analyst intelligence to address the world-over issue of Knowledge Management in RA.
Zen is a virtual analyst who never sleeps, eats or goes on vacations. For sure he will never leave the team (taking his accumulated knowledge with him).
In conclusion, I want all of us to take a moment to step into Janet’s shoes. The pin is in the haystack, and the stack is getting bigger and bigger all the time (due to burgeoning volumes and technology/product complexity). The timelines to find that pin are ever-shrinking, and cost reduction is the call of the hour globally.
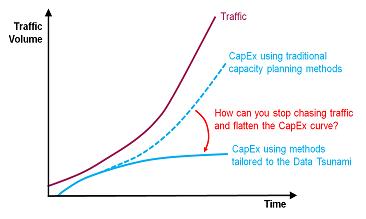
As I interact with more and more service providers about their network capacity issues, I’ve become sure about one thing – what worked before, isn’t really working anymore. The CapEx requirement for network equipment just to keep up with the exponential growth in data traffic (i.e., Data Tsunami) is still not getting them ahead of significant congestion issues and customer impacting events. Why? Traditional capacity management paradigms are not working.
Essentially, feedback from carriers of all sizes and types has exposed one of the most significant shifts in thinking regarding how to go about managing and planning for network capacity. They know that the rules are all changing and today’s content demands are outpacing the CSPs ability to keep pace. The first key question is how to get back in front of the capacity demand (we’ll talk about monetization next…stay tuned). So, why aren’t today’s processes scaling?
CSPs use a multitude of human resources and manual processes to manage network capacity. This may have scaled under slower and more predictable capacity growth curves, but thanks to services like You-Tube & Netflix, entire network capacity is shifting in quantum leaps.
Solutions provided by equipment vendors are often platform specific, and reinforce a silo approach to Capacity Management when a holistic view is needed. Service demand congestion is a network phenomenon which doesn’t care about individual equipment vendors or devices.
CSP planning groups leverage data and make decisions based on systems which have 20 – 40% inaccuracy in comparison to the actual capacity availability in the network.
Today’s CSP solution approach is often homegrown where 90% of the time is spent on acquiring and understanding raw data. As a whole, everyone is trying to answer the question of how to proactively eliminate the possibility of congestion, but most are still focused on addressing the symptoms and not preventing the problem
It is surprising to note that even top tier/technology leaders cannot accurately predict where and when capacity issues will impact their networks. This lack of visibility hurts CSPs considerably because as per our own studies, network events are behind can account for up to 50% of customer churn in high value mobile data services.
And the Capacity Management problem doesn’t really end there; in many ways it’s like a supply chain process. Marketing owns the function of forecasting where service uptake will drive capacity needs across the network. When Marketing underestimates service uptake, there is a real and significant impact to potential revenue: On average, it can take about 3 months from when capacity is fully tapped in a Central Office (CO) to when new capacity can be added to your network. During that time, customers expecting service availability become hugely frustrated and begin to churn. Engineering groups are pushed into panic-mode, trying to react as fast as possible – often putting capacity in the wrong places due to inaccurate data – resulting in further congestion, service degradation, an inefficient use of capital.
The message from CXO’s is crystal clear – there is an urgent and dire need to find new ways of monetizing the data crossing their networks. This need is exacerbated with OTT content and net-neutrality. SLA and authentication based revenue models are absolutely dependent on knowing what types of content/services are traversing your network, how much capacity they consume, and how utilization is driven by your consumer’s interests and activities. This type of analysis requires a critical and intelligent binding of network and services data with business data to truly assess the financial impact to the CSP. Many Business Intelligence (BI) solution leaders will lay claim to abilities here, but actually fall very short of the mark. Instead, real experience suggests that solutions in the marketplace today either:
Can handle the financial aspects of your business but have no understanding of today’s network dynamics in terms of capacity issues and services;
Can handle parts of your network very deeply, but do not correlate or provide a holistic view at the service level; or,
Can collect some network and service level information, but have no ability to incorporate business data to understand the impact to the business – i.e,. cost, subscriber behavior, propensities
All the above challenges bring us to the inevitable question – what kind of approach does one take in order to tackle capacity management issues? How does one stop chasing traffic and focus on flattening the CapEx curve instead? In order to attain ‘Capacity Management Nirvana‘, a proactive and scalable approach needs to be adopted by CSPs. An approach which not only intelligently binds network and business strategies based on the Data Tsunami realities but also brings proactive and predictive capacity management to the table. At the end of the day, a CSP should have access to all their capacity, the ability to leverage real and immediate feedback on the change in capacity as service uptake increases, and finally, the right tools and intelligence to get in front of what’s coming.





 And the Capacity Management problem doesn’t really end there; in many ways it’s like a supply chain process. Marketing owns the function of forecasting where service uptake will drive capacity needs across the network. When Marketing underestimates service uptake, there is a real and significant impact to potential revenue: On average, it can take about 3 months from when capacity is fully tapped in a Central Office (CO) to when new capacity can be added to your network. During that time, customers expecting service availability become hugely frustrated and begin to churn. Engineering groups are pushed into panic-mode, trying to react as fast as possible – often putting capacity in the wrong places due to inaccurate data – resulting in further congestion, service degradation, an inefficient use of capital.
And the Capacity Management problem doesn’t really end there; in many ways it’s like a supply chain process. Marketing owns the function of forecasting where service uptake will drive capacity needs across the network. When Marketing underestimates service uptake, there is a real and significant impact to potential revenue: On average, it can take about 3 months from when capacity is fully tapped in a Central Office (CO) to when new capacity can be added to your network. During that time, customers expecting service availability become hugely frustrated and begin to churn. Engineering groups are pushed into panic-mode, trying to react as fast as possible – often putting capacity in the wrong places due to inaccurate data – resulting in further congestion, service degradation, an inefficient use of capital.






