- SOLUTIONS
- SERVICES
- ABOUT US
- RESOURCES
- CONTACT
MANAGEMENT
ASSURANCE
ECOSYSTEM
¿Por qué la inteligencia artificial impulsó la Gestión de fraude?
La Inteligencia Artificial (IA) no es nueva y ha existido durante décadas. Sin embargo, con el advenimiento del big data y la informática distribuida que está disponible hoy en día, es posible darse cuenta del verdadero potencial de la IA. Desde lo que comenzó como una historia interesante en películas de ciencia ficción hasta programas como Alpha-Go que ha estado venciendo a los humanos, la IA ha ido evolucionando. La Inteligencia Artificial también se ha ramificado en múltiples subcategorías, como aprendizaje automático o machine learning, aprendizaje profundo, aprendizaje de refuerzo, etc.
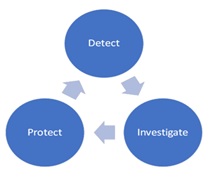
Una estrategia eficaz de gestión de fraudes (FM) incluye 3 pilares importantes: detectar, investigar y proteger. Creemos que la Inteligencia Artificial puede influir positivamente en los 3 pilares de la gestión del fraude, desde reducir los falsos positivos hasta ayudar a extraer el análisis de causa de raíz y crear una mejor experiencia del cliente en protección.
En esta publicación, me gustaría ver el pilar inicial de la estrategia de Gestión de Fraudes: “Detección” y ver la influencia de IA en este paso tan importante. Un enfoque tradicional para la detección de fraudes ha sido a través de motores de reglas que podrían ser:
- Condiciones en caso contrario
- Umbrales
- Expresiones
- Evaluación de patrones de datos
Por ejemplo: para una detección basada en el umbral, los humanos tienen que alimentar el motor de reglas para que el recuento de registros por encima de cierto umbral sea sospechoso.
Los siguientes diagramas muestran cómo se ve esto
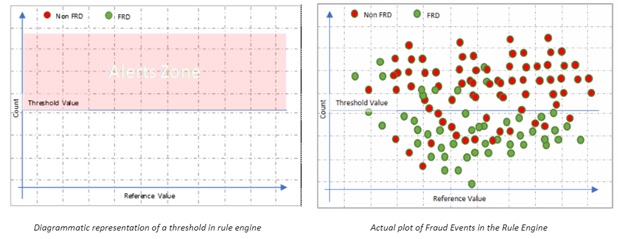
Después de mirar el diagrama anterior, surge una pregunta importante, si este valor de umbral es una línea recta o puede doblarse según el comportamiento de los datos. Ahora hay formas para que el motor de reglas se comporte como se menciona en el diagrama,
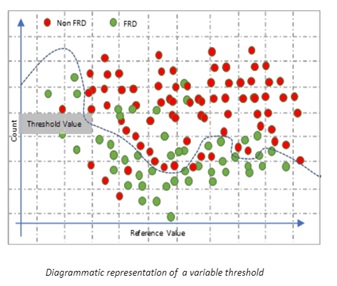
por ejemplo, en lugar de tener una sola regla, tengamos varias reglas
- Por categoría de cliente
- Por destino
- Por edad de los clientes
Y multiplique eso con otras dimensiones en los datos que son
- Número de teléfono
- Número de la persona que llama
- Número llamado
- Código de país
Y multiplique eso con otro conjunto de medidas por dimensiones
- Cuenta
- Duración
- valor
Y arroje mil millones de volúmenes adicionales a los conjuntos de datos


Ahora no digo que los equipos de FM no estén lo suficientemente capacitados para volar, pero un equipo de fraude en un proveedor moderno de Servicios Digitales debería estar más enfocado en otros factores importantes.
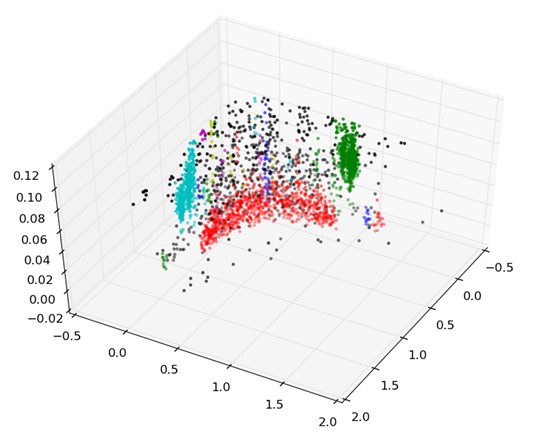
Este enfoque ayuda a lograr múltiples KPIs de equipos de gestión de fraude allí al aumentar la eficiencia.
- Mayor precisión – debido a que la inteligencia artificial puede aprender y adaptarse a los escenarios de negocios más rápido, la inteligencia artificial puede aumentar significativamente la relación positiva verdadera
- Reducción del tiempo de detección – qué tan rápido se puede detectar un evento de fraude
- Autoaprendizaje – cómo, durante un período, los escenarios empresariales cambiantes y la estacionalidad en los datos se pueden adoptar para la detección de fraude
- Inteligencia contra el fraude– cómo se pueden aprender y clasificar los comportamientos del cliente o de cualquier otra entidad para una mejor detección del fraude
- Proactividad – capacidad de extraer patrones desconocidos que no se vieron en los datos anteriormente
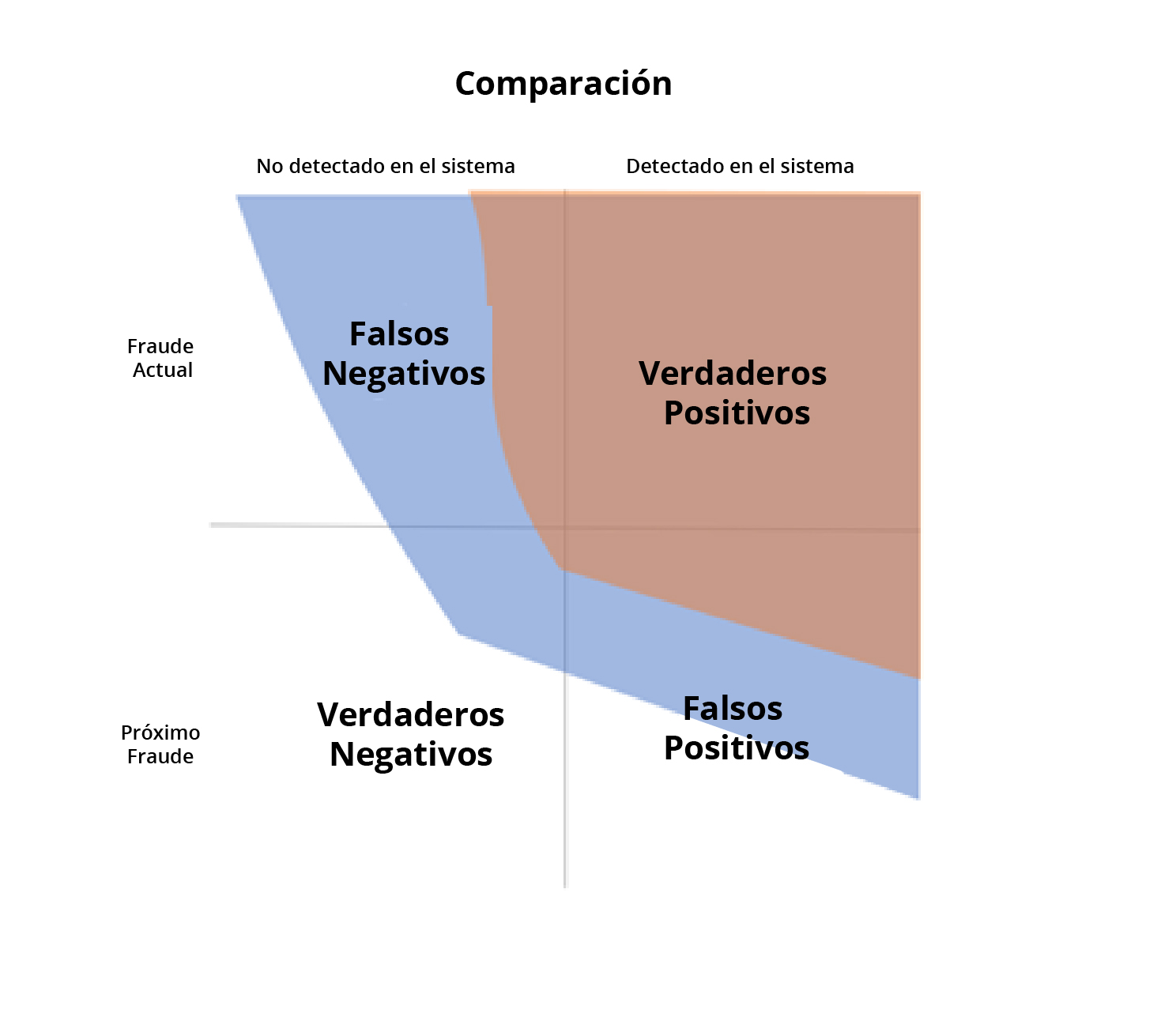
La aplicación de Inteligencia Artificial tiene sus propios desafíos importantes y requiere un nuevo marco de pensamiento, sin embargo, al observar el Tsunami de Datos que ha afectado a los equipos de gestión de fraudes, parece que un enfoque profesional de IA solo ayudaría a los equipos de Gestión de Fraude a escalar aún más.

Nithin has more than 10 Years of experience in Fraud Management. He started his career as an Implementation Consultant with Subex Ltd and has been part of many Fraud Management implementations across APAC & Middle East. He has also been a Subject Matter expert & Business Solution Consultant earlier. Nithin is currently working as Product Line Manager for Fraud Management and machine learning developments at Subex.