- SOLUTIONS
- SERVICES
- ABOUT US
- RESOURCES
- CONTACT
MANAGEMENT
ASSURANCE
ECOSYSTEM
Clustering Algorithms Part 1
To understand clustering, we need to have a basic knowledge of Machine Learning. Machine learning is a subset of Artificial Intelligence that allows a machine to automatically learn from past data without programming explicitly. Classical machine learning is often categorized by how an algorithm learns to become more accurate in its predictions. There are four basic approaches: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. The type of algorithm that data scientists choose to use depends on what type of data they want to predict. Supervised learning is a machine learning approach that’s defined by its use of labelled datasets. These datasets are designed to train or “supervise” algorithms into classifying data or predicting outcomes accurately. Unsupervised learning on the other hand deals with unlabelled datasets. Clustering is an application of unsupervised learning. Semi-supervised learning is a branch of machine learning that attempts to solve problems that require or include both labelled and unlabelled data. Semi-supervised learning employs concepts of mathematics such as characteristics of both clustering and classification methods. Reinforcement learning is a kind of Machine Learning where in the system that is to be trained to do a particular job, learns on its own based on its previous experiences and outcomes while doing a similar kind of a job.
What is Clustering and How it Works?
Clustering is the task of dividing the population or data points into several groups such that data points in the same groups are similar to other data points in that group and dissimilar to the data points in other groups. It is basically an assembly of objects based on similarity and dissimilarity between them.
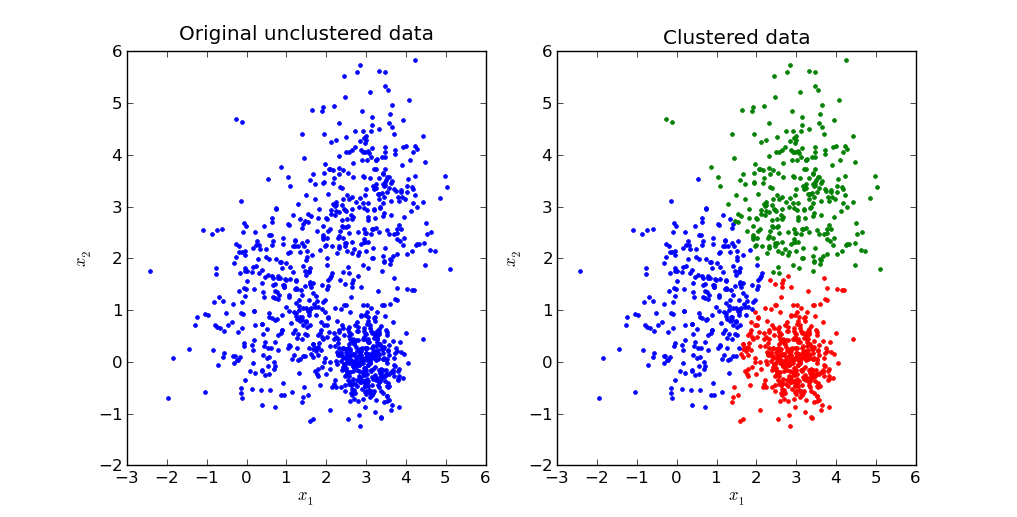
The Importance of Clustering
Clustering helps in understanding the natural grouping in a dataset. Their motivation is to check out to parcel the information into some gathering of legitimate groupings. Grouping quality relies upon the strategies and the identification of hidden patterns. The biggest advantage of clustering over-classification is it can adapt to the changes made and helps single out useful features that differentiate different groups.
The Usage of Clustering Algorithms in Real World
It is widely used in many applications such as image processing, data analysis, and pattern recognition.
It can be used in the field of biology, by deriving animal and plant taxonomies, identifying genes with the same capabilities.
It also helps in information discovery by classifying documents on the web.
It helps marketers to find the distinct groups in their customer base and they can characterize their customer groups by using purchasing patterns.
Different Types of Clustering Methods
Connectivity-based Clustering (Hierarchical clustering)
Hierarchical Clustering is a method of unsupervised machine learning clustering where it begins with a pre-defined top to bottom hierarchy of clusters. It then proceeds to perform a decomposition of the data objects based on this hierarchy, hence obtaining the clusters
Centroids-based Clustering (Partitioning methods)
Centroid based clustering is considered as one of the simplest clustering algorithms, yet the most effective way of creating clusters and assigning data points to it. The intuition behind centroid-based clustering is that a cluster is characterized and represented by a central vector and data points that are in close proximity to these vectors are assigned to the respective clusters.
Distribution-based Clustering
Distribution-based clustering creates, and groups data points based on their likely hood of belonging to the same probability distribution in the data
Density-based Clustering (Model-based methods)
Density-based clustering methods take density into consideration instead of distances. Clusters are considered as the densest region in a data space, which is separated by regions of lower object density, and it is defined as a maximal set of connected points.
Fuzzy Clustering
The general idea about clustering revolves around assigning data points to mutually exclusive clusters, meaning, a data point always resides uniquely inside a cluster, and it cannot belong to more than one cluster. Fuzzy clustering methods change this paradigm by assigning a data-point to multiple clusters with a quantified degree of belongingness metric.
Constraint-based (Supervised Clustering)
The clustering process, in general, is based on the approach that the data can be divided into an optimal number of “unknown” groups. The underlying stages of all the clustering algorithms to find those hidden patterns and similarities, without any intervention or predefined conditions
If you are working with ML algorithms, chances are you will be widely using Clustering. Clustering is an incredibly useful unsupervised machine learning method that has a wide variety of applications.
Get ahead with MLOps. Get better, faster results from your data.
Try HyperSense AI Studio for Free

Siddhant Swaroop Dash is a data scientist at Subex AI labs. He has a keen passion for Artificial Intelligence (AI) and leverages his expertise in Machine Learning to build innovative AI products and solutions for Subex. He is also an integral part of the product team of HyperSense – a revolutionary AI-enabled, augmented analytics platform. He holds a Bachelor’s Degree in Computer Science from the International Institution of Information Technology, Bhubaneswar. His focus is on Deep Learning AI systems involving Computer Vision and Speech. He likes playing basketball and video games in his leisure. His aim is to create a better world using AI.